機械学習の5つの種類
機械学習には、5つの種類が挙げられます。
- 教師あり学習
- 教師なし学習
- 強化学習
- 深層強化学習
- 半教師あり学習
順番に解説していきます。
教師あり学習
教師あり学習とは、人がデータをラベル付けし、それを使用してコンピューターが学習する方法です。
例えば、画像を分類する場合、人が各画像を「猫」「犬」「鳥」などとラベル付けし、それを使用してコンピューターが学習することができます。
その後、コンピューターがデータからパターンを抽出し、新しいデータに対して予測を行います。最後に、学習済みのモデルを元に、新しいデータがどのようなラベルに属するかを予測します。
教師なし学習
教師なし学習とは、教師あり学習の反対で、人がデータにラベル付けをせず、コンピューターがデータからパターンを自動的に抽出する方法です。
例えば、画像を分類する場合、人が「猫」「犬」「鳥」などとラベル付けせず、コンピューターがデータからパターンを自動的に抽出して分類することができます。
この学習方法は、データが不完全な場合や、ラベル付けすることが困難な場合に有効的です。
強化学習
強化学習とは、コンピューターが自分で行動を決定し、その結果によって報酬を得ることで、自己学習する方法です。
例えば、ゲームをプレイする場合、コンピューターが自分で行動を決定し、効率的な行動を選択するようゲームプレイを行います。
強化学習は、複雑なタスクを自動的に行うことができるため、さまざまな分野で活用されています。例えば、ロボット工学や自然言語処理など、人間が行うことが難しいタスクにおいて、強化学習が有効な手法となります。
深層強化学習
深層強化学習とは、深層学習(ディープラーニング)と強化学習を組み合わせた学習方法のことです。
深い層を持つニューラルネットワークを用いることで、より複雑なタスクを学習することができます。
また、高次元の状態空間や行動空間を扱えるため、強化学習の中でも最も強力な手法の一つとされています。
半教師あり学習
半教師あり学習とは、教師あり学習と教師なし学習の両方の特徴を持ち合わせた学習方法のことです。
この学習方法では、一部のデータに対しては正解が与えられていますが、その他のデータについては正解が与えられていない状態から学習を行います。
そのため、データセットが大規模かつラベル付けが困難な場合に有効です。
また、教師あり学習や教師なし学習に比べて、より正確な学習を実現することができます。
機械学習の7種類の手法
続いて機械学習の「手法」について紹介していきます。
機械学習には大きく7種類の手法があり、それについて深ぼっていきます。
- ディープラーニング
- ロジスティック回帰
- ランダムフォレスト
- XGBoost
- LightGBM
- 主成分分析
- クラスター分析
順番に解説していきます。
ディープラーニング
ディープラーニングとは、人間の脳がどのように情報を処理するかを模倣した、多層のニューラルネットワークを用いた機械学習手法のことです。
ディープラーニングでは、入力データを受け取った後、それを多層のニューラルネットワークを通して処理し、出力として結果を生成します。
この手法を用いることで、コンピュータは大量のデータを処理し、高度な抽象化能力を獲得することができます。

ロジスティック回帰
ロジスティック回帰とは、機械学習において、分類問題を解くための手法の一つです。
この手法では、入力データから、そのデータがあるクラスに属する確率を推定します。また、二値分類や多クラス分類など、さまざまなタスクを解くことができます。
そして、非常に単純なモデルであるため、実装が容易であるとされています。
ランダムフォレスト
ランダムフォレストとは、機械学習において、複数の決定木(decision tree)を用いた学習手法の一つです。
この手法では、多数の決定木を用いて、多様な結果を得ることができます。そのため、単一の決定木に比べて、より正確な予測を行うことができます。
また、決定木が多様な結果を生み出すため、過学習(overfitting)しづらい学習方法となっています。
XGBoost
XGBoostとは、機械学習において、勾配ブースティング決定木(gradient boosting decision tree)を用いたアルゴリズムの一つです。
こちらの手法でも、複数の決定木を組み合わせることで、より高い精度を実現することができます。
大規模なデータセットを処理する能力があり、Kaggleなどのデータサイエンスコンペティションで頻繁に使われています。
LightGBM
LightGBMとは、XGBoostと同様に勾配ブースティング決定木(Gradient Boosting Decision Tree)アルゴリズムを用いた機械学習手法の一つです。
この手法では、XGBoostよりも高いスピードで学習を行うことができ、大規模なデータセットに対しても、処理が高速です。
そのため、LightGBMにおいても、Kaggleなどのデータサイエンスコンペティションで広く使われています。
主成分分析
主成分分析とは、教師なし学習の一種で、多次元のデータを少ない数の特徴量に変換する手法です。
この手法では、次元削減のために用いられることが多いですが、データの構造を理解するためにも使われます。
入力データから、主成分と呼ばれる新しい特徴量を抽出し、元の特徴量から得られる情報を最大化しながら、相互に独立しているように設計されます。
クラスター分析
クラスター分析とは、こちらも教師なし学習の一種で、データを自然に分けるグループ(クラスター)に分類する方法です。
この手法は分類とは異なり、入力データをあらかじめ定められたクラスに分類するのではなく、データから自然に生まれるグループに分類するという点で異なります。
クラスター分析は類似したデータをまとめることで、データをより理解しやすくすることができるため、様々な分野で使われます。
機械学習手法の種類を適切に選ぶ方法
機械学習手法の種類を適切に選ぶためには、最初に解決したい問題について把握することが重要です。問題の種類や、データの性質、利用するコンピュータのスペックなどに応じて、最適な手法は変わってきます。
また、機械学習の種類は、教師あり学習(supervised learning)、教師なし学習(unsupervised learning)、強化学習(reinforcement learning)などに大別されます。
さらに、分類(classification)、回帰(regression)、クラスタリング(clustering)、次元削減(dimensionality reduction)など、着地点も大きく分かれています。
そのため、さまざまな要素を考慮しつつ、機械学習手法を決定していきましょう。
なお、上記プロセスを簡単にするために、「scikit-learnのチートシート」を活用することをおすすめします。
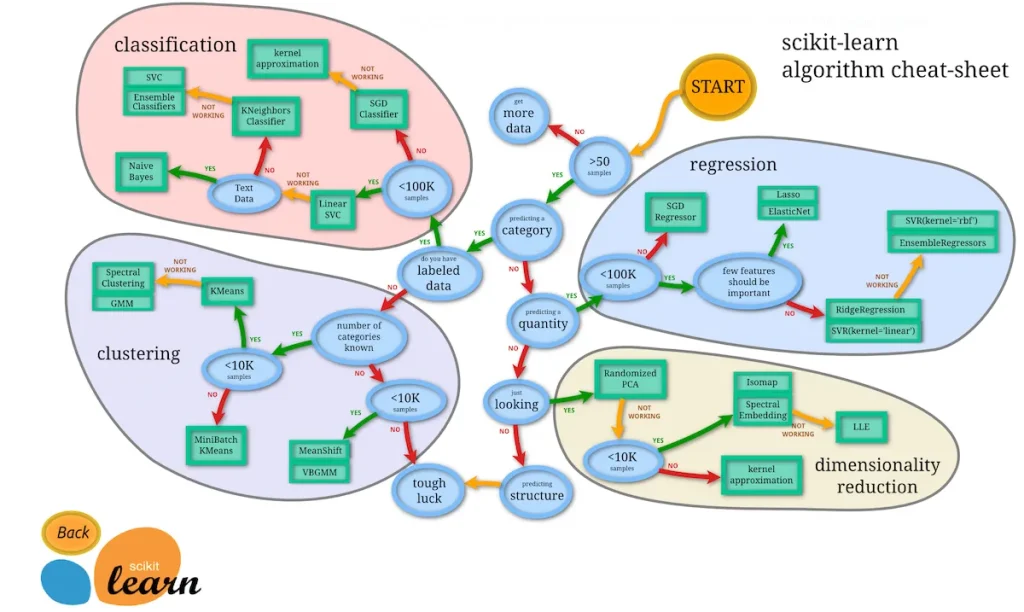
上記表を活用することで、解決したい問題ごとにどの手法を使えばいいかが把握できます。
最初のうちは、どの機械学習手法を使えばいいかまったくわからないかと思いますので、ぜひ有効活用していきましょう。
まとめ:機械学習の種類を理解しよう!
本記事では、機械学習の5つの種類と、7種類の手法について解説しました。
簡単に振り返ると、
- 教師あり学習
- 教師なし学習
- 強化学習
- 深層強化学習
- 半教師あり学習
- ディープラーニング
- ロジスティック回帰
- ランダムフォレスト
- XGBoost
- LightGBM
- 主成分分析
- クラスター分析
それぞれの特徴を理解した上で、有効的に使い分けることができるようにしていきましょう。