機械学習のモデルとは?
そもそも機械学習とは?
機械学習とは、コンピュータが既存のデータから分析を行い、そこからデータの背景にあるパターンを学習する技術のことを指します。
また、その学習した結果をもとに、自動的に予測や分類などを遂行する人工知能技術の一つです。
そのため、複雑なタスクを人間の手を借りず機械のみで実行できるようになり、画像認識やテキストの自動翻訳など、私たちの日常生活の中で使わない日はない存在になりつつあります。
機械学習のモデルとは?
機械学習のモデルとは、任意の問題を解決するためにコンピューターが自動的に学習し、解決までアプローチするためのアルゴリズムや方法のことです。
機械学習のモデルを作成する際には、あらかじめ大量のデータを用意し、それを用いてモデルが自動的に学習を行うよう構築します。
つまりは、機械学習のプロセスは「データの入力→モデルによる学習→データの出力」であるというわけです。
学習させたモデルを通して、人間が定めた問題をより効率的かつ正確に解決できるようアウトプットとして出力されます。
機械学習のモデルが重要である理由
機械学習のモデルが重要である理由は、課題解決に直接関わってくるからです。
いくら良質なデータが揃っていたとしても、そもそものモデルが良くなかったり、不適切なモデルを適用していたとすると、求めるアウトプットを得ることができません。
そのため、機械学習において、モデルの選択や作成は慎重に行う必要があります。
また、モデルは常に改善が必要です。新しいデータや状況が発生した場合、モデルを適切に更新し、それに適応させることが求められます。
機械学習の代表的な7種類のモデル
続いて、機械学習のモデルについて詳しく紹介していきます。
機械学習には代表的なモデルが7種類あり、それぞれについて深ぼっていきます。
- ディープラーニング
- ロジスティック回帰
- ランダムフォレスト
- XGBoost
- LightGBM
- 主成分分析
- クラスター分析
順番に解説していきます。
ディープラーニング
ディープラーニングとは、人間の脳がどのように情報を処理するかを模倣した、多層のニューラルネットワークを用いた機械学習手法のことです。
ディープラーニングでは、入力データを受け取った後、それを多層のニューラルネットワークを通して処理し、出力として結果を生成します。
この手法を用いることで、コンピュータは大量のデータを処理し、高度な抽象化能力を獲得することができます。

ロジスティック回帰
ロジスティック回帰とは、機械学習において、分類問題を解くための手法の一つです。
この手法では、入力データから、そのデータがあるクラスに属する確率を推定します。また、二値分類や多クラス分類など、さまざまなタスクを解くことができます。
そして、非常に単純なモデルであるため、実装が容易であるとされています。
ランダムフォレスト
ランダムフォレストとは、機械学習において、複数の決定木(decision tree)を用いた学習手法の一つです。
この手法では、多数の決定木を用いて、多様な結果を得ることができます。そのため、単一の決定木に比べて、より正確な予測を行うことができます。
また、決定木が多様な結果を生み出すため、過学習(overfitting)しづらい学習方法となっています。
XGBoost
XGBoostとは、機械学習において、勾配ブースティング決定木(gradient boosting decision tree)を用いたアルゴリズムの一つです。
こちらの手法でも、複数の決定木を組み合わせることで、より高い精度を実現することができます。
大規模なデータセットを処理する能力があり、Kaggleなどのデータサイエンスコンペティションで頻繁に使われています。
LightGBM
LightGBMとは、XGBoostと同様に勾配ブースティング決定木(Gradient Boosting Decision Tree)アルゴリズムを用いた機械学習手法の一つです。
この手法では、XGBoostよりも高いスピードで学習を行うことができ、大規模なデータセットに対しても、処理が高速です。
そのため、LightGBMにおいても、Kaggleなどのデータサイエンスコンペティションで広く使われています。
主成分分析
主成分分析とは、教師なし学習の一種で、多次元のデータを少ない数の特徴量に変換する手法です。
この手法では、次元削減のために用いられることが多いですが、データの構造を理解するためにも使われます。
入力データから、主成分と呼ばれる新しい特徴量を抽出し、元の特徴量から得られる情報を最大化しながら、相互に独立しているように設計されます。
クラスター分析
クラスター分析とは、こちらも教師なし学習の一種で、データを自然に分けるグループ(クラスター)に分類する方法です。
この手法は分類とは異なり、入力データをあらかじめ定められたクラスに分類するのではなく、データから自然に生まれるグループに分類するという点で異なります。
クラスター分析は類似したデータをまとめることで、データをより理解しやすくすることができるため、様々な分野で使われます。
機械学習手法のモデルを適切に選ぶ方法
機械学習手法のモデルを適切に選ぶためには、最初に解決したい問題や目的を明確にすることが重要です。問題の種類や、データの性質、利用するコンピュータのスペックなどに応じて、最適な手法は変わってきます。
そのため、さまざまな要素を考慮しつつ、機械学習手法を決定していきましょう。
- 問題や目的に対して、どのアプローチ方法が適切か
- 学習データや計算リソースは十分にあるか
- モデルの性能はどのくらい必要か
- モデルが過学習や汎化性能に対して、どうか
なお、上記プロセスを簡単にするために、「scikit-learnのチートシート」を活用することをおすすめします。
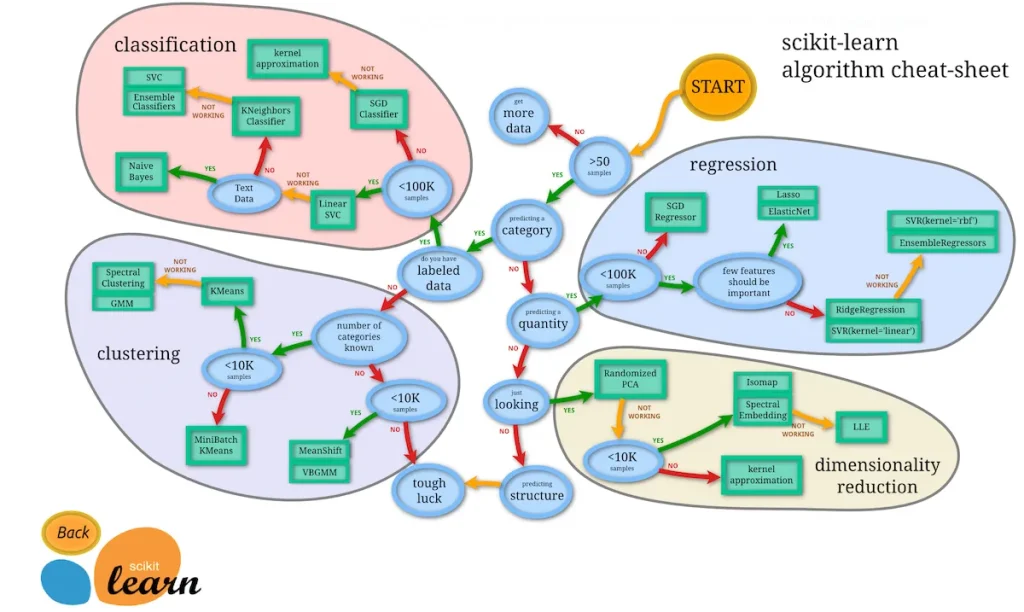
上記表を活用することで、解決したい問題ごとにどの手法を使えばいいかが把握できます。
最初のうちは、どの機械学習手法を使えばいいかまったくわからないかと思いますので、ぜひ有効活用していきましょう。
まとめ:機械学習のモデルを適切に構築しよう
本記事では、機械学習モデルの定義から重要性、代表的なモデルや選定方法について解説しました。
機械学習モデルは、データ分析の課題解決に直接関わってくるので、適切に選定して構築できるようにしていきましょう。
また、その際は「scikit-learnのチートシート」などを活用して、効率的に進めていきましょう。